- elasticsearch-definitive-guide-en
- Introduction
- 1. Getting started
- 2. Distributed Cluster
- 3. Data In Data Out
- 4. Distributed CRUD
- 5. Search
- 6. Mapping Analysis
- 7. Query DSL
- 8. 056_Sorting
- 9. Distributed Search
-
10.
070_Index_Mgmt
- 10.1. 05_Create_Delete
- 10.2. 10_Settings
- 10.3. 15_Configure_Analyzer
- 10.4. 20_Custom_Analyzers
- 10.5. 25_Mappings
- 10.6. 30_Root_Object
- 10.7. 31_Metadata_source
- 10.8. 32_Metadata_all
- 10.9. 33_Metadata_ID
- 10.10. 35_Dynamic_Mapping
- 10.11. 40_Custom_Dynamic_Mapping
- 10.12. 45_Default_Mapping
- 10.13. 50_Reindexing
- 10.14. 55_Aliases
-
11.
075_Inside_a_shard
- 11.1. 20_Making_text_searchable
- 11.2. 30_dynamic_indices
- 11.3. 40_Near_real_time
- 11.4. 50_Persistent_changes
- 11.5. 60_Segment_merging
-
12.
080_Structured_Search
- 12.1. 05_term
- 12.2. 10_compoundfilters
- 12.3. 15_terms
- 12.4. 20_contains
- 12.5. 25_ranges
- 12.6. 30_existsmissing
- 12.7. 40_bitsets
- 12.8. 45_filter_order
Add Failover
Running a single node means that you have a single point of failure--there is no redundancy. Fortunately, all we need to do to protect ourselves from data loss is to start another node.
Starting a Second Node
To test what happens when you add a second node, you can start a new node in exactly the same way as you started the first one (see running-elasticsearch), and from the same directory. Multiple nodes can share the same directory.
As long as the second node has the same cluster.name as the first node (see
the ./config/elasticsearch.yml file), it should automatically discover and
join the cluster run by the first node. If it doesn't, check the logs to find
out what went wrong. It may be that multicast is disabled on your network, or
that a firewall is preventing your nodes from communicating.
If we start a second node, our cluster would look like cluster-two-nodes.
A two-node cluster--all primary and replica shards are allocated
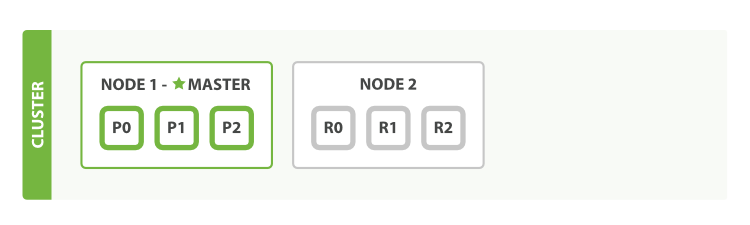 Figure 2.4.1. A two-node cluster--all primary and replica shards are allocated
Figure 2.4.1. A two-node cluster--all primary and replica shards are allocated
The second node has joined the cluster, and three replica shards have been allocated to it--one for each primary shard. That means that we can lose either node, and all of our data will be intact.
Any newly indexed document will first be stored on a primary shard, and then copied in parallel to the associated replica shard(s). This ensures that our document can be retrieved from a primary shard or from any of its replicas.
The cluster-health now shows a status of green, which means that all six
shards (all three primary shards and all three replica shards) are active:
{
"cluster_name": "elasticsearch",
"status": "green", (1)
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 3,
"active_shards": 6,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}
(1) Cluster status is green.
Our cluster is not only fully functional, but also always available.